Cargar las dimensiones de un data warehouse
CronoTL;DR;
OK. Pedazo de artículo con 300 líneas de código y más de 1000 palabras que no apetece leer. Te lo resumo para que decidas si continuar: SQL es un lenguaje difícil de escribir, las herramientas ETL tradicionales asi asá, y Crono SQL mola.
Todo argumentado con ejemplos y buen humor. Nada debe tomarse demasiado en serio. :-)
Sáltale la introducción si ya sabes lo que es una SCD.
Introducción
En otros artículos he hablado sobre la carga de dimensiones y he explicado que las tablas de dimensión se caracterizan por cambiar su contenido poco a poco. Por ese motivo, se las conoce como "dimensiones lentamente cambiantes" o "dimensiones de variación lenta". En inglés se llaman "slowly changing dimensions" o simplemente SCD.
Me refiero, concretamente, a estos artículos antiguos:
De todos modos, estas consideraciones son bastante irrelevantes, ya que todas las dimensiones son lentamente cambiantes, y aunque fuesen "rápidamente cambiantes" se cargarían exactamente igual. Por ese motivo, hablaremos simplemente de la carga de las dimensiones de un data warehouse.
Existen 2 maneras de cargar una dimensión:
- SCD Tipo 1: Se sobreescriben los cambios
- SCD Tipo 2: Se guarda la historia de cambios
En este artículo me referiré solo a la carga de dimensiones Tipo 1, que son las más sencillas. Tal vez otro día hablaré de las de Tipo 2, que mostrará aún mejor el argumento de este artículo.
Conceptualmente, cargar una dimensión tipo 1 es trivial. Sencillamente queremos sobrescribir los valores del data warehouse con la información vigente en nuestro ERP. Si existe algún registro nuevo, lo añadiremos. Si algún registro ha cambiado, lo actualizaremos. Eso es todo. Parece trivial. Pero, ¿Lo es? Lamentablemente, no tanto...
Para mostrarlo, veremos las alternativas que existen para desnormalizar la información de producto de la base de datos AdventureWorks. El modelo de datos es el siguiente:
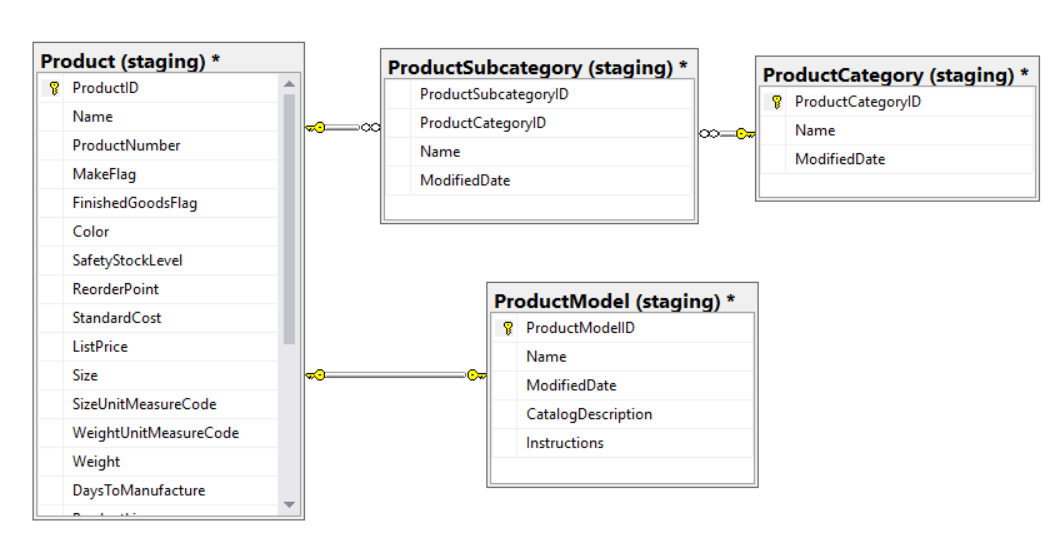
Cargar dimensiones SCD Tipo 1 con SQL
La consulta para obtener los campos que necesitamos es muy sencilla. A esta operación se llama "desnormalizar". En esto el lenguaje SQL es muy bueno. La consulta es esta:
Sin embargo, cargar estos datos en la tabla DimProducts es absurdamente complejo. Por este motivo, cada programador lo hace distinto. Algunos priorizan el rendimiento, otros valoran la facilidad mantenimiento, otros son más pragmáticos y priorizan terminar el desarrollo as soon as possible. El lenguaje SQL es terrible para esto.
Lo más sencillo es eliminar la tabla y recargarla cada día. Este seria el código:
Este método lo considero muy desaconsejable. Por un lado, obtendría el peor rendimiento, y además impediría mantener la integridad con el resto de tablas (...existen ventas asociadas a estos productos que estamos eliminando), por lo que se deberían desactivar las claves foráneas o incluso prescindir de ellas totalmente. Tampoco te permitiría mantener la clave subrogada ni mantener campos de auditoría. Por lo tanto, por favor, no lo hagas así.
Si yo tuviese que escribir el código SQL para cargar la tabla DimProducts probablemente haría un INSERT para añadir los registros nuevos y un UPDATE para actualizar los cambios.
Me gusta este método porque el código no es excesivamente complejo. Sin embargo, el rendimiento no sería óptimo, porque estamos actualizando todos los registros, hayan cambiado sus valores o no. De todos modos, incluso con dimensiones de pocos millones de registros el rendimiento puede ser aceptable (si tenemos buen hardware y no excesivas columnas....).
Si el rendimiento es un problema, deberemos modificar el código para actualizar solo los registros que han cambiado. Aquí la cosas se empiezan a poner feas. ¿Os he dicho que el lenguaje SQL es ridículamente complejo para esta necesidad taaaaaaan habitual en DWH?
Este es el código necesario para hacerlo "bien":
También existe la instrucción MERGE que te permite realizar el INSERT y el UPDATE en un solo paso. Así debes escribirlo si quieres hacerlo "bien bien":
Como se observa claramente, la dificultad aparece en el momento de comparar, campo a campo, si algún registro ha cambiado. Es una dificultad solo para el programador, ya que con esta sintaxis el motor de la base de datos está más feliz que un gínjol. No hay relación entre longitud y complejidad del código y rendimiento. Cualquier motor de base de datos es muy eficiente con este tipo de comparaciones. Es solo trabajo de CPU. Comparar unos y ceros para confirmar que la dimensión apenas ha cambiado desde la carga anterior... Actualizar los cambios, insertar los nuevos, ¡y listos!.
Si miras una vez más el último código, que consideramos "fetén", entenderás que nadie lo haga así. Nadie. Los programadores -los conozco bien- harán todo tipo de asunciones equivocadas para evitar eso, o se montarán una macro Excel que se lo genere, o harán una metaquery de una query que genera parte del código, o defenderán con razón la necesidad de adquirir una herramienta ETL... (nadie es perfecto)
Cargar dimensiones SCD Tipo 1 con herramientas ETL
Las herramientas gráficas son a los procesos ETL/DWH lo mismo que el WYSIWYG a la programación de páginas web. Deberás diagramar en un flujo de procesos la lógica de la carga. Tras haberlo intentado con SQL, te convencerán fácilmente de las bondades de este tipo de herramientas:
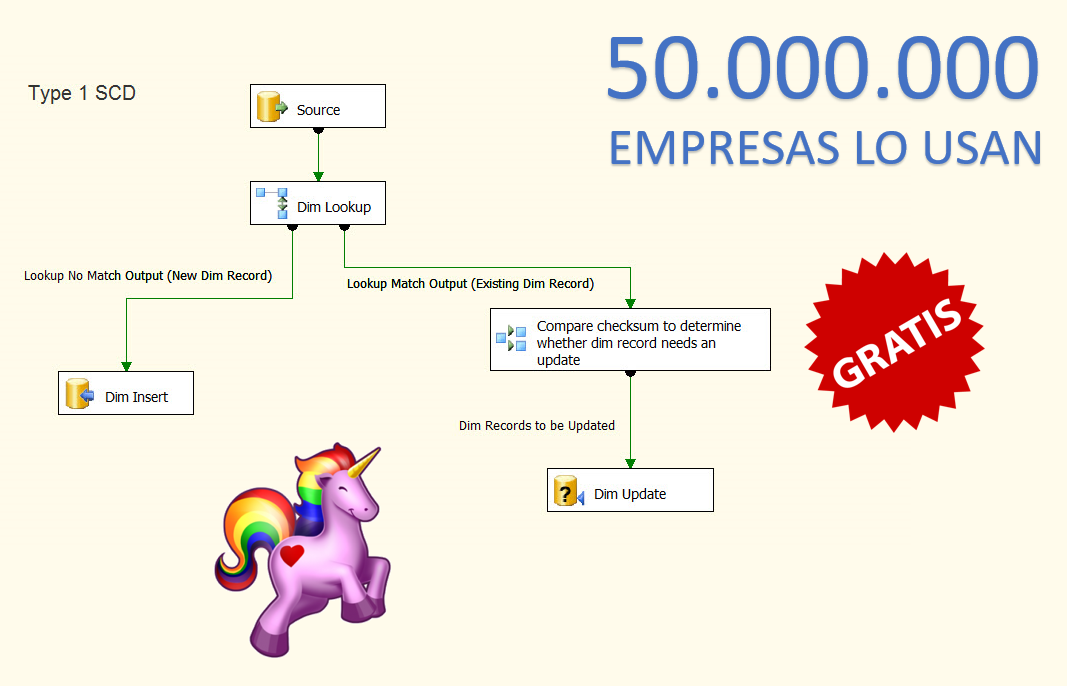
Debo aclarar que estoy hablando siempre de herramientas ETL destinadas a la construcción de un DWH. Para otras necesidades de integración, las herramientas ETL no son solo fantásticas, sino que son imprescindibles. Sin embargo, para ETL/DWH, mi opinión sobre las herramientas gráficas ETL no es extraordinariamente positiva y, de hecho, hay algunas cosas que sería necesario mejorar. No son siempre tan tan buenas como nos las pintan. Asi es como yo veo el anterior diagrama:
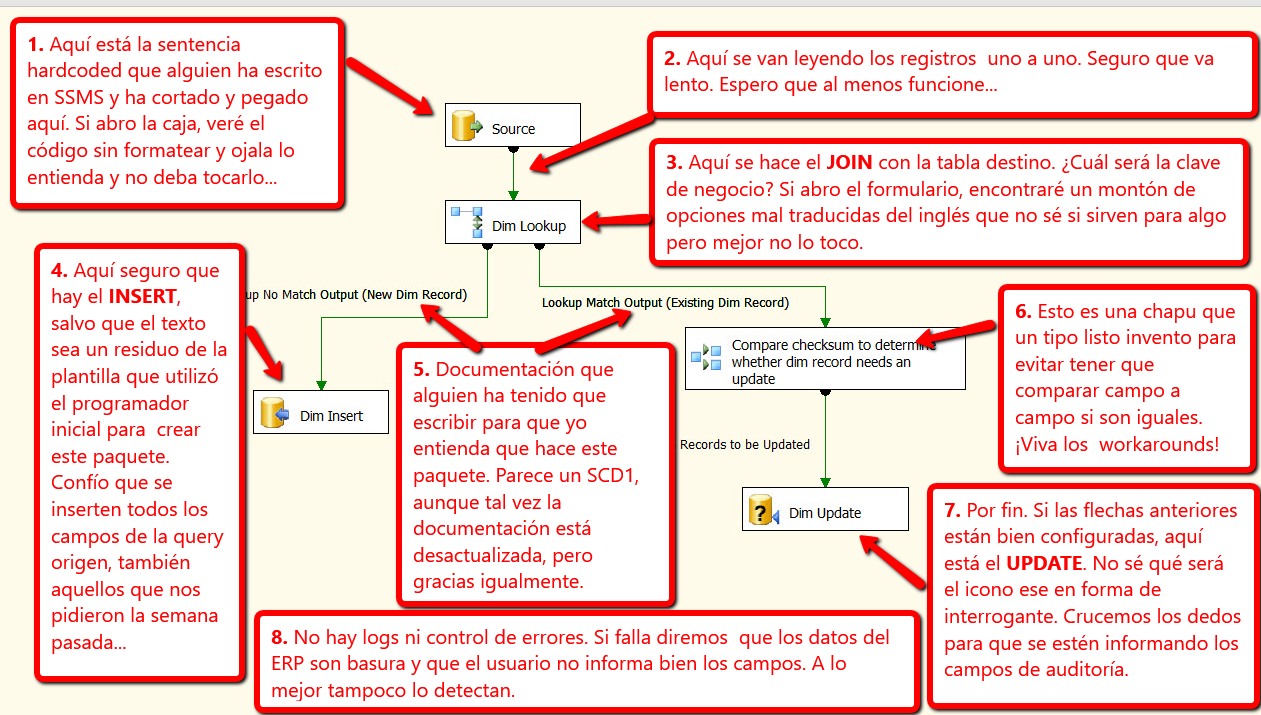
De acuerdo. Se me ha visto el plumero. Soy muy crítico con las herramientas ETL y me cuesta encontrar sus virtudes. Además tengo intereses comerciales. En cualquier caso, en mi defensa, debo decir que las conozco y que opinaba exactamente igual hace 15 años cuando me tocó trabajar con ellas. Pero quiero ser ecuánime y contrarestar mi evidente sesgo. Por eso, queridos lectores, agradeceré si utilizáis los comentarios para completar el artículo con un link a un buen tutorial sobre como cargar dimensiones con SSIS, Kettle, ODI o PowerCenter... No lo hago yo por no parecer tendencioso en la elección. :-)
Tal vez, las herramientas ETL facilitan algo el desarrollo y bastante el mantenimiento posterior. Y digo "tal vez" porque conozco proyectos fallidos que me obligan a cuestionarlo.
Si hace tiempo que utilizas una herramienta ETL, tal vez has olvidado por que empezaste a utilizarlas. Tal vez es algo que te encontraste cuando llegaste y nunca has cuestionado... ¿Por qué usamos herramientas gráficas para programar procesos ETL/DWH? ¡Porque escribir SQL eficiente es difícil, farragoso, aburrido y propenso a errores! ¡Y porque el mantenimiento de un proyecto complejo porgramado en SQL es básicamente imposible! ¿Las seguirías utilizando si el SQL no tuviera estos defectos? ¿En serio?
Cargar dimensiones SCD Tipo 1 con Crono SQL

Se hace así:
Fácil. QED.
Síguenos
Recuerda que podéis apuntaros a nuestra newletter sobre Business Intelligence o seguirnos en redes sociales:
- La newsletter de Business Intelligence fácil
- Linkdin Crono Business Intelligence
- Twitter @bifacil
- Facebook Crono Business Intealligence
Gracias por la atención. Gracias por difundir.